+1 619-349-4911
+1 619-349-4911







Java developers, while creating complex applications, need to store and retrieve persistent data in less time. Java is an object-oriented language that implements an object model. Whereas a relational database management system represents data in a table format. Both the models were different from each other on how they load or store objects. On using RDBMS, they encountered a problem called “object-relational impedance mismatch” or “paradigm mismatch,” which means that the object model and the relational model do not work well with each other. The four main reasons for this are-
- Granularity – It is the extent to which a system can be broken down into small parts. In the object model, you can have objects in various levels of granularity, but in the relational model, granularity is limited to only two levels—tables and columns.
- Inheritance mismatch – The relational database does not support inheritance, while the object model has the concepts of subtypes or inheritance in it.
- Identity mismatch – In the relational model, the sameness of two entities is defined only by their primary key. If they have the same value as their primary key, they are considered identical. However, java defines both object identity and object equality.
- Associations mismatch – Association in object model is achieved by object references whereas in the relational model we use a foreign key to associate two entities.
These challenges led to the development of tools specifically designed to support ORM (Object Relational Model). Tools like EclipseLink, iBatis and Hibernate all support ORM, but these tools were sub-standard and dependent on vendors. This is the reason why JPA came into existence!
What is JPA?
Java Persistence API or JPA is a specification that acts as a bridge between Java objects/classes and a relational database. The API is defined in the javax.persistence package and provides many interfaces for querying and managing data. It also provides JPQL which is similar to SQL, but instead of querying a database, we can query a java object. To use JPA we need to annotate our java classes to map them to tables and columns. Once we have fully annotated our class, JPA takes care of the CRUD (Create, Read, Update, and Delete). JPA provides the entity manager, which handles the loading and persisting of the data to the database automatically. Instead of formulating queries towards the database, we can use JPQL to make queries to java classes. We can now focus on java objects instead of worrying about interacting with the underlying database.
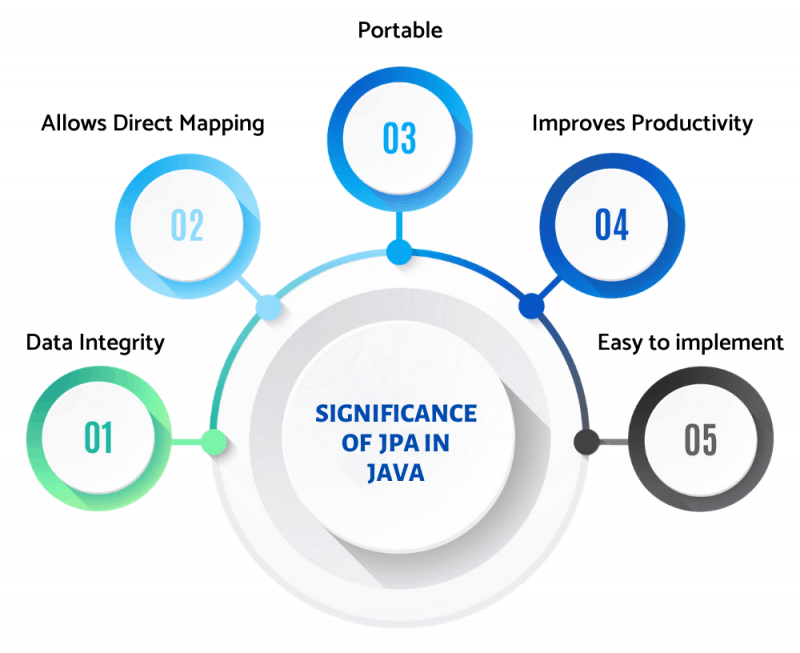
Significance of JPA in Java
- Data Integrity – JPA can easily deal with large data sets and provides data consistency, which makes it more beneficial than serialization. In serialization, the entire object graph needs to be stored and retrieved at once, which makes it difficult to use while dealing with large amounts of data. Moreover, the changes made in the objects can’t be undone if an error occurs whenever there’s an information update. These issues don’t occur in JPA, thereby resulting in higher efficiency for applications that demand strict data integrity.
- Allows Direct Mapping—Unlike JDBC, JPA provides a direct mapping between the Java objects and database tables. While using JDBC, a large chunk of code requires mapping between the data sets and objects. Apart from this, JDBC implements logics via SQL which makes it less efficient than JPA.
- Portable – The ORM and ODB frameworks don’t use a strict standard, which results in a lack of portability between different vendors. So, while using ORM and ODB, developers encounter an issue of vendor lock-in. Vendor lock-in is a situation in which if you want to switch to another product or vendor, you have to rewrite the entire persistence code again. This issue is resolved by using JPA. It has a strict standard that allows you to easily switch between products of different vendors making it portable and more effective.
- Improves Productivity—JPA enhances productivity, as it is very easy to use and provides developers with an API that is very effective in implementing CRUD operations. While using JPA, the developers don’t need to map tables and domain models multiple times. It also supports concurrent access to information and can easily deal with a large amount of data thus increasing productivity.
- Easy to implement – JPA doesn’t require the usage of DDL and DML in a database-specific dialect of SQL. Instead, it uses annotations, which reduces the use of SQL coding, making it less complex for developers. While using JPA, there is no need for using DTO, DAO, and SQL, as it works on the ‘entity class,’ and the coding of the processing can be done by considering the object of the entity class as if it is directly stored in the database. Thus, JPA works directly with the objects instead of dealing with SQL commands.
To develop robust and high performing applications, the Java Developers need to opt for a technology that is efficient enough to deal with large amounts of data within less time and is easy to use. JPA is a specification that supports transactional integrity, advanced OO-concepts and requires fewer resources as compared to JDBC and other frameworks. The famous implementations of JPA include Hibernate, TopLink, EclipseLink, and Apache openJPA that are doing great in the IT-industry. JPA is better than other frameworks as it consumes less time and is cost-effective.
About SynergyTop
Synergytop develops robust software solutions and enterprise applications using Java. We will assist you in selecting the right java architecture, as well as apply best practices and methodologies. Synergytop has experienced a software development team to design winning software and web applications using java.
Are you looking for a java development partner who can help you develop solutions for your clients? We can help!